FINALLY
Wordle 238 2/6*



FINALLY
Wordle 238 2/6*
Daily Dordle #0019 3&4/7

Daily Quordle #19




nerdlegame 24 3/6

Surprisingly few possible words left after the first two guesses.
Wordle 238 3/6*
Wordle 238 2/6
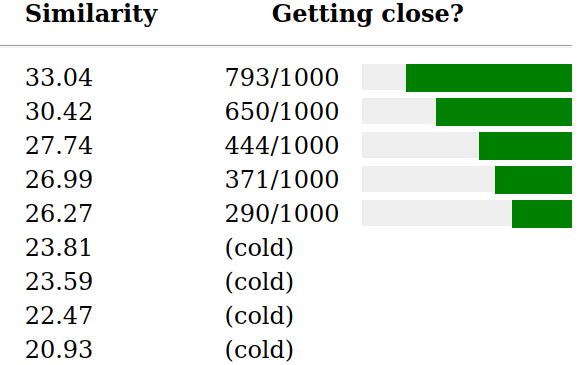
I didn’t draw green until 72 and best guess was 110. I’m at 200 now and ready to give up.
Wordle 238 3/6
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Daily Quordle #19
![]()
![]()
![]()
![]()
quordle.com
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
Tied my PR on quordle. So much luck though, all first 3 correct guesses had other common possibilities. Stared at bottom right forever before coming up with it.
Got the semantle in 133, a record, with two other people participating. My strategy of typing in rhyming or alliterative words works to get unstuck. I randomly typed a word based only on seeing the starting letter on the keyboard, and binked a 978 when we were on 407. The 407 came from a rhyming jag.
Getting to 1000 from 978 was indeed easier with multiple people.
Daily Quordle #19


Daily Dordle #0019 3&5/7
Wordle 238 4/6*
Wordle 238 3/6*
Wordle following up yesterday’s with the only word I could think of until I came upon yesterday’s answer.
Probably linguistics, but even then it’s a specialized branch known as natural language processing which is sort of a joint subfield of linguistics, compsci, and statistics. I think the thing that would help the most is having some understanding of the algorithm, the tuning parameters used, and selection of corpus. We aren’t given a ton of insight into those things from the game creator other than it’s word2vec with all parts of speech, proper nouns, and short phrases.
Yeah, that’s possible. I have a little bit of experience doing this with another technique called stylometry which is similar. In stylometry, you feed the computer corpora of text from known authors to train the model, then use that model to make probabilistic classification for texts with unknown authors. For example, it could be used determine whether uncredited passages were likely written by Shakespeare. The core mechanism of this model is breaking a corpus into tokens (usually words in this case) and n-grams (a consecutive strong of n tokens). The frequency of particular tokens and n-grams is like an author’s stylistic fingerprint, and the algorithm does some fancy math to make predictions about attribution.
Word2vec uses similar concepts to the token / n-gram approach but with a different objective function: instead of author to token/n-gram relationships, it’s solving for token/n-gram to token/n-gram relationships using techniques called continuous bag of words (CBOW) and skip-grams which fall under the umbrella of word embedding techniques:
The main objective here is classifying words in context such that one could (1) predict words that are likely to surround a target word and/or (2) predict words that could be used as substitutes for the target word. There are many approaches to modeling this, but they all essentially do the same thing: generate n-dimensional vectors for words such that words that are contextually similar are closer in n-space than those that are not. In other words, think of a word vector as a row (or column) of numbers of length n. For example, the vector for the word banana may look like this if we cap the number of dimensions to n=3:
[.8 -.2 .07]
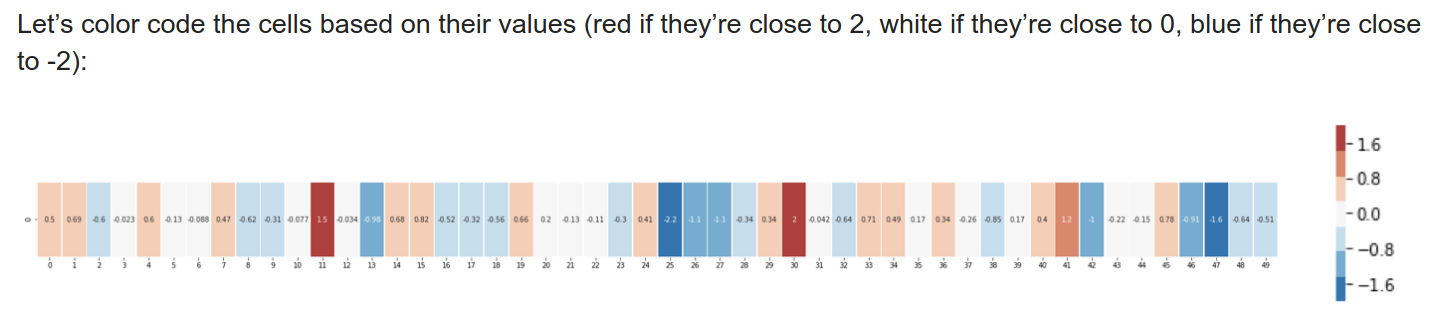
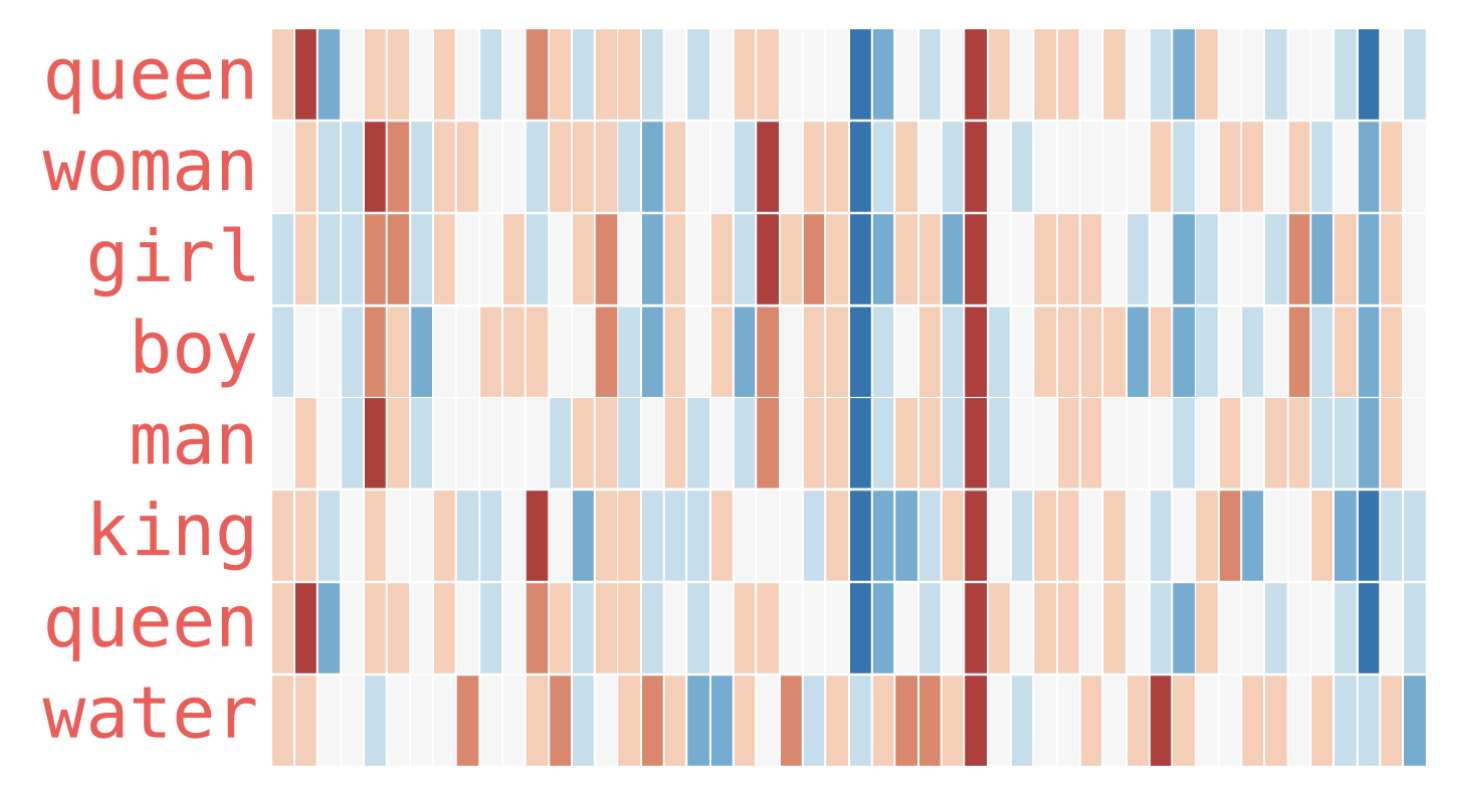
You could perhaps imagine this as the XYZ location of “banana” in 3-D coordinate space or whatever. In practice, the number of dimensions is gonna be way higher in order to capture anything meaningful, so trying to picture it as a location in high dimensionality doesn’t really make sense. Instead, we might convert the values in each dimension to color (strengths) in order to compare similarity visually, as this person has done here:
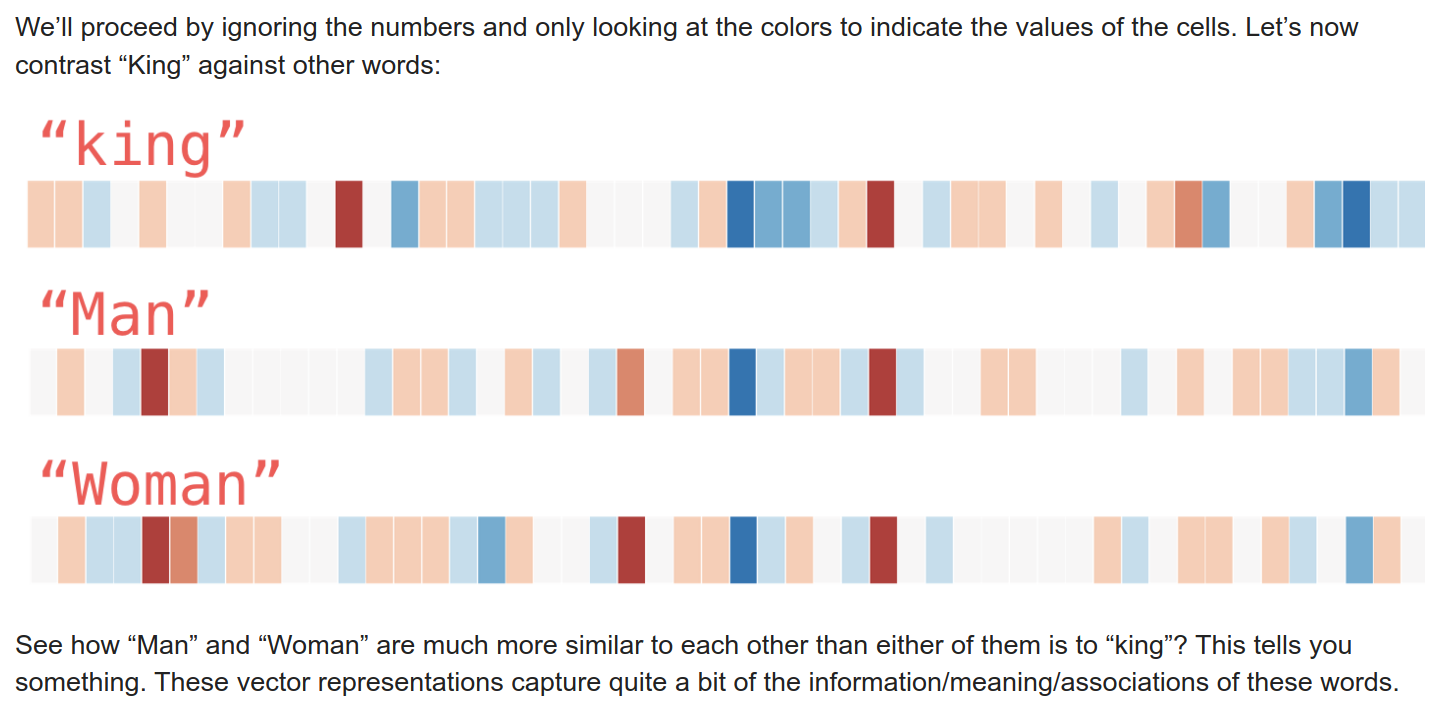
That might be the best visual representation of what this particular “game” is, i.e., lighting up the same positions (dimensions) on the vector of the target word. It’s pretty easy to see how you can get trapped here though, or perhaps easier to see in this image:
All of these load onto one dimension. Does it mean anything? In the strictest sense, these are just abstract mathematical relationships and have no meaning; in practice, it’s common to attach meanings to dimensions because that’s how our brains work. Regarding the game, the problem should be clear. You might hit a word that’s close (top 1000) to the target, but then subsequently rattle off related words that load on the same dimensions but get you no closer to the answer.
Anyway, here’s an example of why the corpus matters a whole lot–the best positive match for love is you when trained on this corpus:
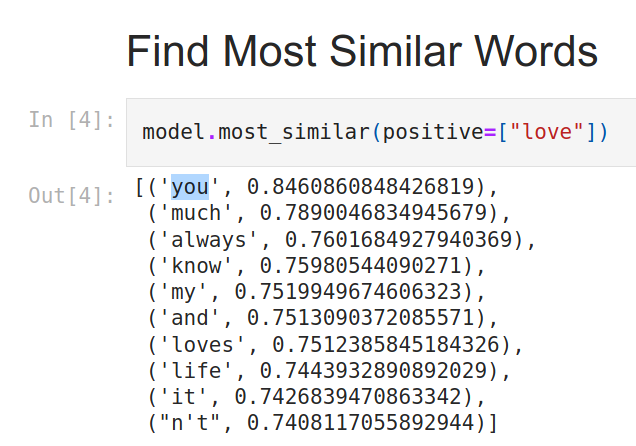
Which corpus could produce these results?
I’d guess that using a large corpus of Tweets is going to produce significantly different results from, say, the works of Shakespeare as the training data. Knowing the corpus gives us meta-clues about how words are going to be used. And not just that, but these models are sensitive to parameterization. So while I think the idea for Semantle is quite clever, I’d suspect a significant amount of pruning / tweaking is required to produce a version that plays well and doesn’t seem so erratic.
Seems that the function of the word matters a lot. For example, I’m on a streak of basically guessing every single word in the top 1000 but the correct word by getting its use and likely its part of speech correct.
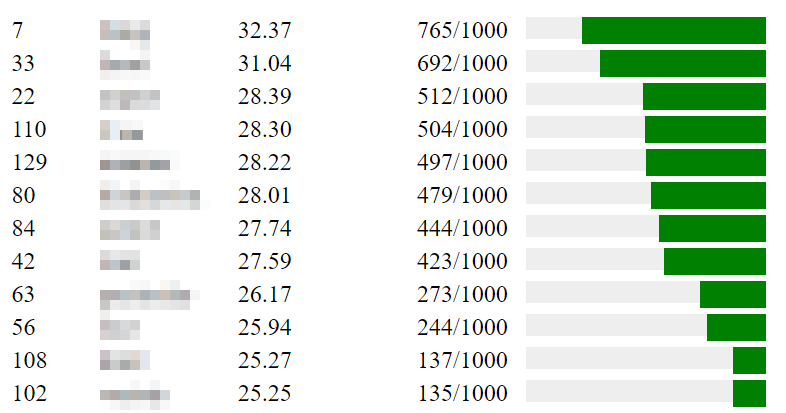
Took 115 guesses but I got it
Dunno how you all got this one. I had to fire up a word2vec instance in Google colab and cheat to get there, and even then it took a lot of trying based on my initial starting point of words it told me were close that definitely were not close. Total of 263 guesses.
Really feels like many of the higher scores (from ~250 to 1k) are for words that appear around the target word, not words that could be substituted for the target word. Hypothetical: ‘heavyweight’ should not score highly in similar meaning to ‘undisputed’ but I think it would here. If that’s true, then the algo is scoring context in a way that can derail you. Would be nice to know how the parameters are set.
If you want to cheat at Semantle or maybe just get an idea of what’s happening under the hood, you can try it here (at your own risk, this isn’t my code):
Run the first three blocks in order, then skip to the last one:
#Inbuilt
word_vectors.most_similar(positive=['woman', 'king'], negative=['man'], topn=1)
Enter as many words as you like for positive, remove the negative parameter altogether, and set topn for the number of hits you want returned:
#Inbuilt
word_vectors.most_similar(positive=['demolition'], topn=25)
You’ll see the true hits that get returned including capitalized words, compound words, phrases, and misspellings. Semantle only uses “normal” words for targets aka lowercase single words eliminating misspellings, weird accent marks, etc. I had a few runs where most of the top matches were spelling errors and weird punctuation / diacritics, and the sensible matches were few and far between.
Try entering today’s target word once you know it and look at the results. Notice that if you multiply the algorithm scores by 100, you’ll get exactly the numbers returned by the game.
Daily Quordle #19

Should’ve been 3-5-6-7 but I fired off guess #6 without enough thought.
I’ve actually trained word2vec on legal corpora as part of work. The word embeddings are quite different, thus providing mathematical proof that legalese is infact its own language!
In any case the notion of similarity here is purely mathematical and overlap with semantic similarity (as that infamous king + queen - man = woman) illustrates while not entirely uncorrelated is not causal.
Also I gave up after 40 or so tries as I was stuck cycling in the teens.
Took my first serious try at Semantle today and got it in 135 guesses. Spazzed out a little and went in the wrong direction after getting a 994, could have gotten it in like 10 less, but I’m happy.
My 10th guess was 996/1000
From there, I went all over the place until I found the function of the word.
Not exactly sure what you mean. Are you saying if you train it on legal corpora, it produces totally different results compared to training it on English literature or a Twitter scrape?
The relationships are definitely mathematical and don’t have true meaningful interpretations. However, in academia you’re supposed to just nod your head and play along while an emperor with no clothes converts a large vector of real numbers into an English language explanation that just happens to perfectly match his theory. But avoiding that, there are a ton of ways to tweak the algorithm / loss function to affect what similarity means in a mathematical way, and I’m not sure what’s being used here is necessarily the best for this type of game.
Results:
| Word1 | Word2 | Cos_Sim |
|---|---|---|
| heavyweight | middleweight | 0.688 |
| heavyweight | bantamweight | 0.624 |
| heavyweight | boxer | 0.514 |
| heavyweight | champion | 0.412 |
| heavyweight | rematch | 0.380 |
| heavyweight | fight | 0.362 |
| heavyweight | title | 0.331 |
| heavyweight | undisputed | 0.316 |
| heavyweight | ring | 0.311 |
| heavyweight | mat | 0.277 |
| heavyweight | heavy | 0.257 |
| heavyweight | big | 0.256 |
| heavyweight | world | 0.256 |
| heavyweight | belt | 0.245 |
| heavyweight | sport | 0.223 |
| heavyweight | ropes | 0.215 |
| heavyweight | athlete | 0.178 |
| heavyweight | former | 0.131 |
| heavyweight | fat | 0.113 |
| heavyweight | large | 0.108 |
| heavyweight | rope | 0.103 |
| heavyweight | tomato | 0.073 |
| heavyweight | dense | 0.055 |
| heavyweight | dangerous | 0.016 |
| heavyweight | custard | 0.003 |