It looks like the data was actually available.
https://twitter.com/stgoldst/status/1407494774236483586
IDK why they deleted it but doesn’t seem to be a coverup.
It looks like the data was actually available.
https://twitter.com/stgoldst/status/1407494774236483586
IDK why they deleted it but doesn’t seem to be a coverup.
Buried in a published paper!
If Bloom is right that this data points towards covid circulating around Wuhan before the cluster of cases at the market, then it’s obviously notable. And if he’s right that the deletion led to this fact being obscured for more than a year, then that’s notable as well. I’m not remotely qualified to judge either claim but Bloom certainly is.
https://twitter.com/PacificChorus/status/1407502585779560450?s=20
Huh. Submitted to one journal, removed and sent to another. Def the way they would handle their secret gain-of-function research they’re hiding from the world, no need to check in with the publishers or authors before accusing everyone of massive fraud.
If you read Bloom’s tweet thread you would know he isn’t accusing anyone of massive fraud and that he did ask the authors why they deleted the database entries.
No one seems to think he’s accusing them of fraud, but of a nefarious coverup of…something…something that must be really bad because they’re covering it up, use your imagination from there.
I was responding to Trolley Trollson:
But Bloom doesn’t really hint at anything, he says outright why he thinks the deletion is notable:
https://twitter.com/jbloom_lab/status/1407445633695305728
https://twitter.com/jbloom_lab/status/1407445637063274498
https://twitter.com/jbloom_lab/status/1407445638636208130
https://twitter.com/jbloom_lab/status/1407445639655346176
https://twitter.com/jbloom_lab/status/1407445640628477952
https://twitter.com/jbloom_lab/status/1407445641609957380
https://twitter.com/jbloom_lab/status/1407445642574630913
Right, the coverup is limited only by our imaginations.
I guess I’m not following your objection? Bloom is couching his opinions here in cautious and conditional language, which seems prudent.
Because he’s taking all these conditionals as flowing from a flawed premise, that the data were hidden, when in fact they were merely moved. He doesn’t acknowledge that, however.
Why consider any other possibilities when you can run to Twitter to accuse people of “burying” data? They’re Chinese, after all.
Bloom’s article is actually surprisingly accessible to a layman, in case anyone is interested. Not saying I understood everything but it was quite interesting.
This is kind of the crux of the deletion:
The fact that such an informative data set was deleted has implications beyond those gleaned directly from the recovered sequences. Samples from early outpatients in Wuhan are a gold mine for anyone seeking to understand spread of the virus. Even my analysis of the partial sequences is revealing, and it clearly would have been more scientifically informative to fully sequence the samples rather than surreptitiously delete the partial sequences. There is no plausible scientific reason for the deletion: the sequences are perfectly concordant with the samples described in Wang et al. (2020a,b), there are no corrections to the paper, the paper states human subjects approval was obtained, and the sequencing shows no evidence of plasmid or sample-to-sample contamination. It therefore seems likely the sequences were deleted to obscure their existence. Particularly in light of the directive that labs destroy early samples (Pingui 2020) and multiple orders requiring approval of publications on COVID-19 (China CDC 2020; Kang et al. 2020a), this suggests a less than wholehearted effort to trace early spread of the epidemic.
I’m having trouble understanding what’s going on. The paper seems to say that some sequences were uploaded to a public archive, then subsequently removed. And then parallel to that, a paper was published that included a description of those samples, which included a control number (but not the actual sequences? Not exactly sure about that). And then the author was able to use the control numbers to reverse-engineer a URL where the sequences might be accessible and found most of them.
Is that all correct? If so, it seems very different from taking the sequences down from one archive and uploading them somewhere else. It seems like trying to take them down and just tripping up on a technical detail that leaves them recoverable. I guess it’s also relevant whether the sequences are reconstructible from what’s in the published paper.
Right. Obviously the partial sequences weren’t published in the table in the paper, although it does include point mutations in the samples. If the partial sequences weren’t important why would Bloom go through all the trouble of honing his hacking skills to recover them?
This is the table in question:
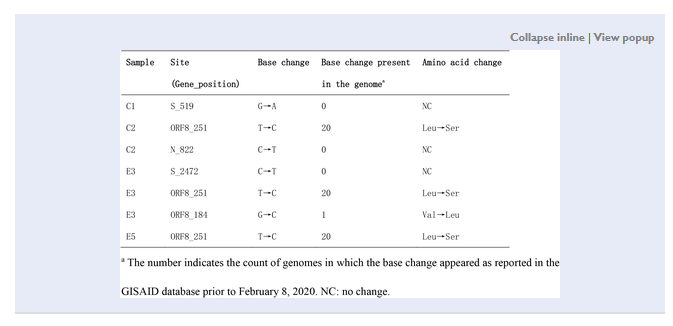
This isn’t a rhetorical question, by the way, I don’t know the answer and don’t think it’s obvious. My intuition is that the point mutation tells the whole story? But the raw data was obviously important to Bloom.
And the fact that it seems like no virologist had heard of the paper in question kind of supports what Bloom is saying here. Virologists apparently don’t read that journal, but if those sequences were in the databases they were deleted from, they’d have been analyzing them more than a year ago.
There are any number of reasons why you might do something like this. People pull stuff all the time after realizing there might be an error in the data, or maybe they don’t want to be accused of “double-dipping” (publishing the same data in two different journals). I’m sure if you send a team of Crack Internet Sleuths to track down every odd idiosyncrasy you’re going to find all manner of boring things that could be made to seem vaguely suspicious.
What do other actual scientists say about Bloom’s paper?
https://twitter.com/michaelzlin/status/1407588811127726086
https://twitter.com/ras_nielsen/status/1407460273582133253
Professor Stuart Neil, a virologist at Kings College London, told the Telegraph : “This is prima facie evidence that there were certain authorities in China wanting to obfuscate some of the early evidence of what was going on in a way to maybe cloud the issue a little bit.
“And the big question is what were they trying to obfuscate. There is really important forensic molecular epidemiology that has to be done to try and trace the origins of this.”
