Leaving this here for me: Good post I found about calculating server load requirements. He mentions a really interesting autoscaling implementation project that could be done.
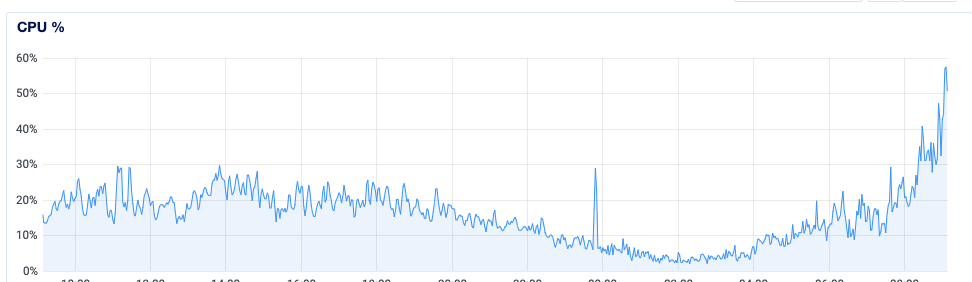
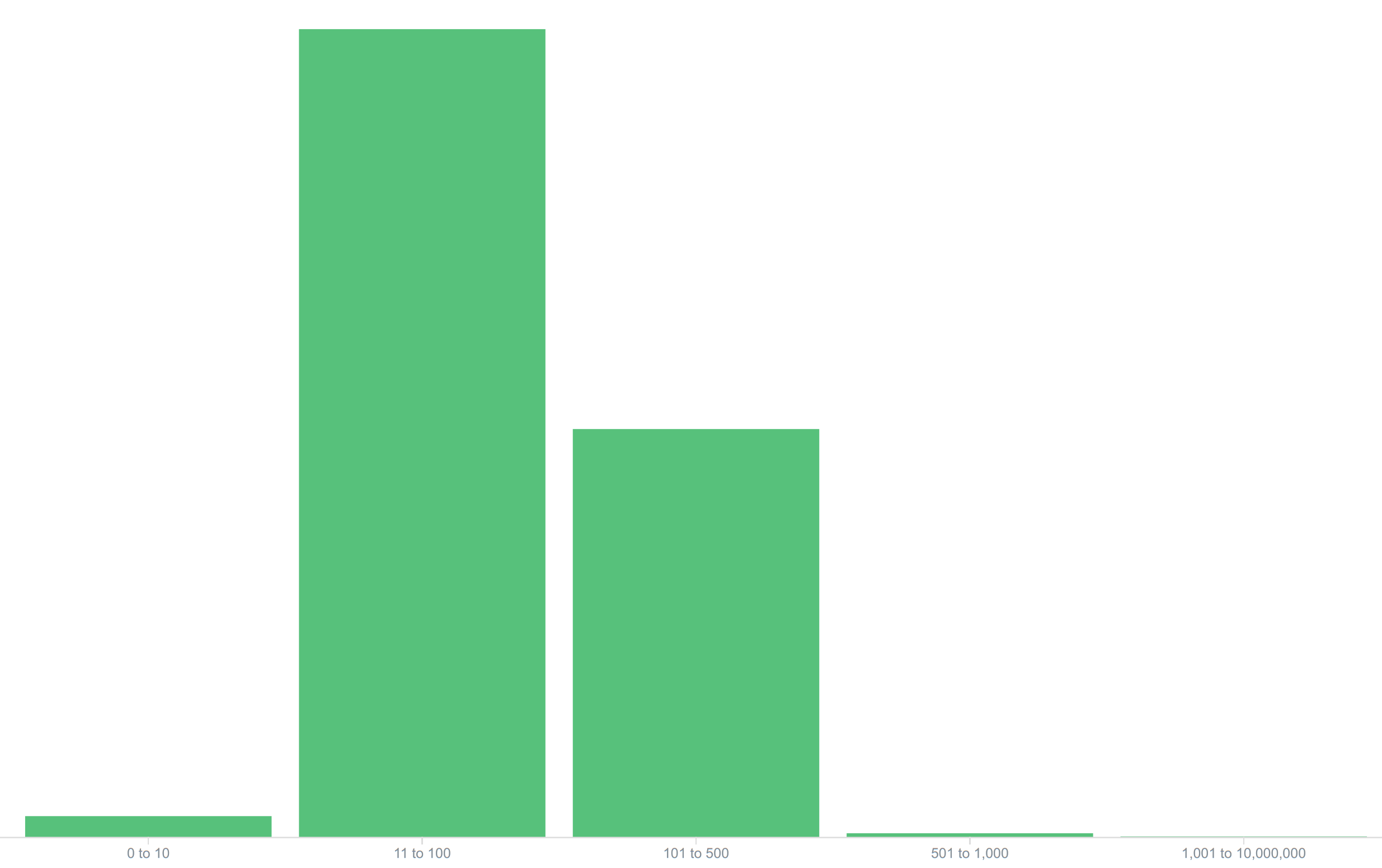
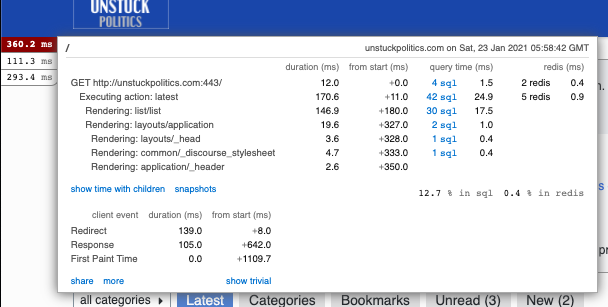
Number of posts made is about the least interesting metric, even more so over such a long time period. Page views is far, far more relevant for determining needed resources. It can be a bit tricky to compare the requests and traffic patterns of a “traditional” mostly-server-generated forum to a Discourse forum, because Discourse is very API-driven, so we often serve multiple HTTP hits per “page view”, but we tend to service each HTTP request a lot quicker, so the forum appears to be a lot more responsive to the user, as shown by this breakdown of just dynamically-generated response times:
Most page-generation-oriented “traditional” forums would, for the same level of user behaviour, probably have a lower volume of requests, but they’d be pushed a lot further to the right; it’s rare for a traditional forum to be generating a majority of responses in under 100 milliseconds.
I’m not putting up that graph to brag about how good Discourse is (although it is rather impressive, IMBO), but rather to highlight that the way you think about provisioning capacity for a Discourse site can be a little different to how you’d figure out how many, say, php-fpm workers to keep in stock.
A typical, say, Magento site (which I dealt with a lot in my previous role) might take 1000ms or more to generate a page (I shit you not; Magento is a dog ). You’d factor on having to have at least one php-fpm worker per pageview-per-second, to guarantee no contention. As soon as you have any sort of request rate in excess of your capacity, user experience goes straight to hell because every queued request is going to be adding a full second to the TTFB because it’s waiting behind another request that’s also taking a whole second to process.
Discourse, on the other hand, is making many smaller requests, so even if (and that’s a big “if”) it took a second’s worth of requests to render a page, with each of them taking somewhere around 100ms, the apparent responsiveness of the site is improved, because each request gets serviced quicker. This is the same principle at work as OS multitasking: keep the time slices as small as possible to improve interactive responsiveness, even if it costs a little more in context switch overhead.
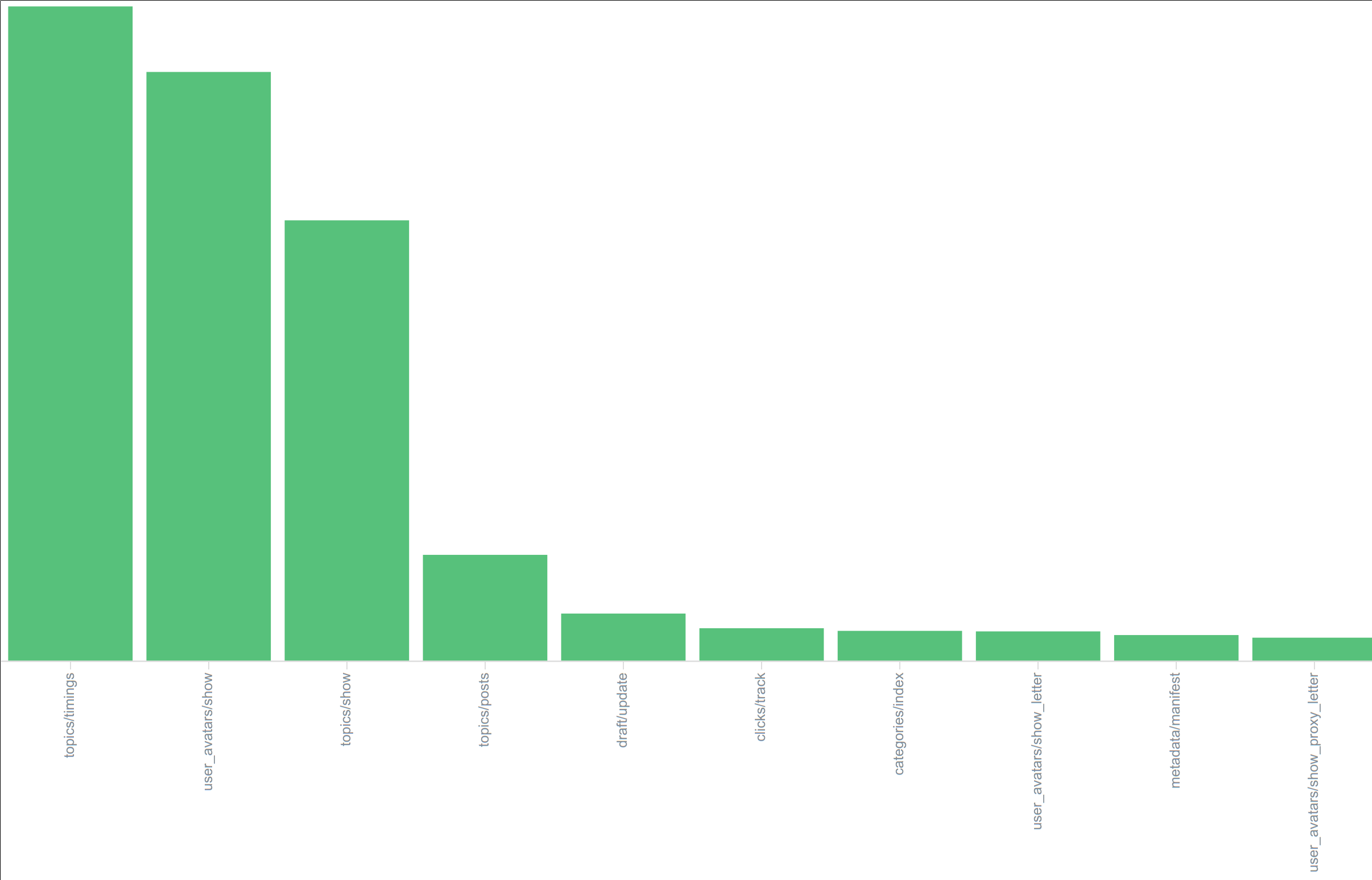
Even then, though, most of the requests that a Discourse site processes via unicorn are purely “async”, tracking activity and so on. For example, here’s a relative breakdown of the routes that are most often hit:
(Y-axis scale deliberately filed off, because it isn’t the exact numbers that matter, it’s the relative weightings)
Leading the pack is topic/timings , which is a purely background (async) route that gets POST ed to to record “this user took this long to read these posts”, which counts towards both the “how long has someone spent reading” (for trust level calcs, amongst other things) and also the little “how long does it take someone to read this topic” data that comes up when you load long topics.
The next route by request volume, showing avatars, is dynamic because avatars come in a ridiculous number of sizes, so we often have to regenerate new ones. Worst case, a single “show me some posts” request could result in 20 requests to the various avatar display routes, but that’s pretty rare because usually most avatars have been seen before and have been cached.
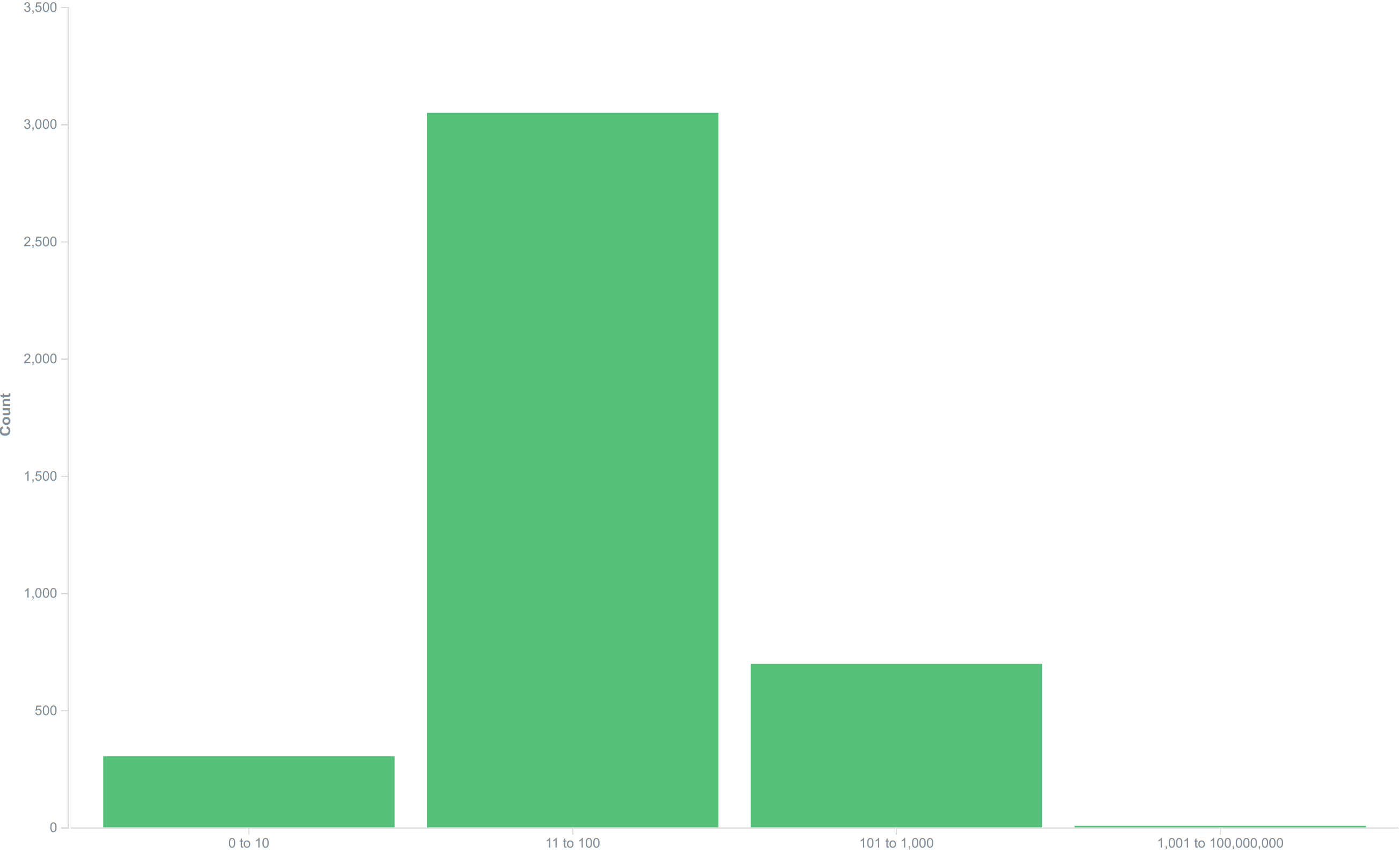
It’s topics/show and topics/posts where we start to get to into what would normally be considered “page views”, and even then, performance is pretty solid, with the majority of responses being made in under 100ms, as shown by this graph of the aggregate of response times for topics/show and topics/posts :
(I split the 100-1000 group in half, just to show we weren’t cheating with a lot of nearly-one-second responses or anything)
One thing you’ll note isn’t on the list of frequently hit routes is posts/create . While draft/update gets hit a fair bit (pretty much any time someone updates a draft post they’re working on, they’ll hit that route in the background ), actual post creation doesn’t happen very often, relative to reading. So, a metric of “we get N posts per day” doesn’t say much at all about actual site traffic. Attempts to extrapolate from number of posts made to total traffic volume are very sensitive to the read/write ratio used in the calculation, and since the read/write ratio varies greatly between different sites, you end up with some very wide ranges of estimated site traffic. You’re far better off just measuring it for your actual site and using those numbers for your scaling calculations.
The rule of thumb I would apply to figure out how big Discourse app servers needed to be, on a dedicated site, would be as follows:
- Determine how many page views per second I wanted to cater for, at absolute peak. My definition for “page view” would be something like “viewing a list of a subset of topics, or viewing a subset of posts in a topic”. How to determine that from an existing forum’s traffic data depends on exactly how the existing forum software works. Completely ignore all other requests, because they work very differently in Discourse, and will be accounted for in the rest of these calculations anyway.
- Divide your desired peak “page views per second” by two, to get the total number of unicorns you need to run to service that volume of traffic. Looking at some ratios of “total time spent in Unicorns to page view rate”, they seem to vary between about 0.29 and 0.35, on the ridonkulously fast CPUs we use, so on the slower CPUs you usually see in cloud providers, it’s a reasonable estimate that you can service about two concurrent page views per second worth of requests per unicorn.
- Now you know how many unicorns you need, divide that by two to get how many CPU cores you need, and multiply it by 300MB to get your unicorn RAM requirements.
- Get as many machines of whatever size you need to satisfy those needs. Tack on a maybe a half a GB of RAM and a half a CPU core per machine for “system overhead” and disk cache.
Et voila! App server capacity calculation done.
Running those calculations, for a site with very peaky load, you’ll probably come out with a number that makes you go a bit pale. It’s probably a lot more droplet than you were expecting to need. That’s because you’re calculating based on absolute peak requests, and you only get those maybe 1% of the time. This is where cloud elasticity comes in handy. You don’t need to be paying for all those droplets all the time, so turn 'em on and off as you need to.
The big cloud players, like AWS, give you shiny autoscaling logic for “free” (which mostly seems to involve making the rulesets easy to screw up so you rapidly cycle instances up and down, which makes your bill bigger), but if you’ve got a sensible monitoring system like Prometheus (big plug: we use it here at CDCK and it is delightful ) you can setup your own autoscaling triggers to fire up a new droplet when CPU usage starts to go bananas, and kill off a droplet when things slow down, pretty easily. You need to wire up service discovery and a few other bits and pieces to make it all work, but it can save you a bucketload of money and it’s fun to build. Even if you don’t want to go that wild, if you know when your peaks are likely to be (say you’re running a forum for enthusiasts of a particular sport, and there’s “off-season” traffic levels, “in-season” traffic levels, and “finals” traffic levels) you can setup more droplets when the traffic levels are going to be predictably higher, and then turn 'em off after everyone goes away again. In each case, you work out your droplet requirements based on the peak page views in each group and the above calculations. It won’t save you as much money as doing it dynamically, and if you get a bigger surge of traffic than you expect at finals time you might get overloaded, have a poor user experience for a bit, and need to add some more emergency capacity (assuming your monitoring system let you know that things Went Bad), but it’ll still be a lot cheaper than running peak-capacity droplets 24x7x365.
Or, you just throw your hands in the air, figure you’ve got better things to do than fiddle around with all this stuff yourself, and just drop a small  on our doorstep to have me and the rest of the CDCK ops team take care of all this for you.
on our doorstep to have me and the rest of the CDCK ops team take care of all this for you.