Sorry Karen, but your kids couldn’t paint that. The pros make it look easy, but it takes more than a smartphone and a false sense of expertise to actually be good at things that require skill. Or does it? It turns out that there’s a growing community of people generating digital art using artificial intelligence [insert “always has been”].
One of the more intriguing developments on this front is text to image generation which is exactly as it sounds: you type in some words and the robot painter starts working on your masterpiece. After messing around with some GUIs that were hit or miss, I located ThE sAuCe which is a Python codebook. No programming required, just have to change one parameter, i.e., the text that you’d like to generate an image of. This may seem too obvious, but I went with “Picasso Power Ranger with glitter” for my first run. Here are the results.

This is some truly horrifying stuff right here and a giant Harold burger based on other results I’d seen using this technology. Luckily, this was only the first image it produced and I quickly realized that it wasn’t finished. By default, the code is set to spit out an image every 50 iterations.

(100) Still a horror show.

(150) Ok now that’s pretty interesting and artistic. Maybe we’re going places.

(200) We’re going places.

(250) Possibly the Louvre.

(300) Not better or worse, just different. It’s riffing effortlessly.
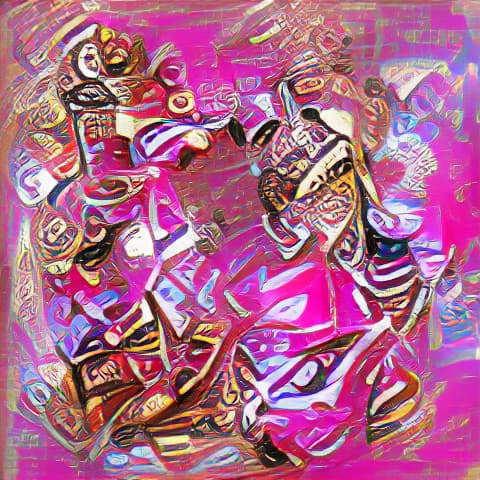
(350)

(400) Could be imagining things but I’m starting to see a Power Ranger take shape?

(450) This is where I got spooked. From this point up to #2300, the changes between images are subtle, so I’m going to jump to the final image in the sequence.

(2300) And there it is. Picasso Power Ranger with Glitter. I am completely mesmerized and humbled by this robot’s ability to create elite art.
*Edit: If you’re new, try one of these two simple GUI interfaces. You really just need to change the text prompt to whatever you want it to paint:
You can upscale your image to a higher resolution with AI here:
There are many forks of this now, but the original implementation was by advadnoun and then this Google Colab codebook by Katherine Crowson in the link below. *Those early versions may be a bit dated at this point depending on the type of image you’re trying to generate. The VQGAN+CLIP method seems to be inferior to CLIP-guided diffusion (posted later in thread) for photorealism.
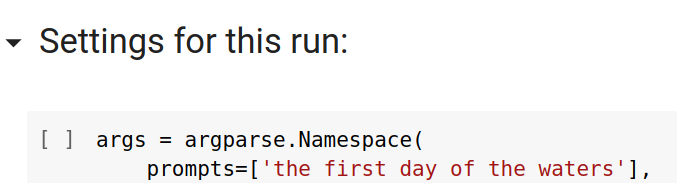
You need to run the sections of code in order using the play button, and some of them take a while. Under the SETTINGS FOR THIS RUN section, change the text between quotes in prompts = ["the first day of the waters"], to the text you’d like to create an image of.
Tips: Using an artist’s name or writing “in the style of [artist]” seems to work well if you’re going for a certain look. If you pick something too esoteric, it may get stuck and not have a reference image for your thing (some of my other attempts were huge fails). Some people report that adding “unreal engine” to the end can generate rendered scenes with more realism. Also, there are additional operators you can use like | to separate fields but you should read documentation on those.
Here is a list of more implementations of the algorithm combo that produces the images:
Let’s see if anyone can beat Picasso Power Ranger with Glitter in this thread.





 Does this symbolize him rising above the Pope?
Does this symbolize him rising above the Pope?
 My greatest heroes in one painting!
My greatest heroes in one painting!







