don’t you need to rebase if master moved forward and touched the same lines?
1 Like
Ok, sorry, nm. I googled something that I wanted and the result said rebase and I didn’t investigate. I can find the working commits on main after the merge without rebase and that’s what I wanted.
At this point I’m just using add/commit/push/pull/merge …mostly…
I was accumulating branches and no one will ever care about them, so I just made a working branch for myself and I “git reset —hard main” on that branch when I start something new there. Should that be a “fetch” instead?
Source Tree is next to godliness imo. It does all this stuff for you and I can see at a glance if I have any changes to the 30 or so repos I contribute too - either from me, or from someone else.
Don’t fall for that hipster command line BS. Every time I show them “discard file/chunk/lines” in SourceTree they’re like, “oh that’s nice, yeah I can’t do that easily on the command line”.
challenge me
I’m generally operating on the linux subsystem of my windows machine and don’t even have a graphical interface. Essentially everything I do is from the command line.
1 Like
And that’s a great workstation! That’s mine and I love it. I get the windows user experience with the flexibility of a realistic linux environment. Yea, there are things wrong with it, but it just works for normal development.
1 Like
And before anyone says you can do all of that on a mac, my laptop cost less than $350 new.
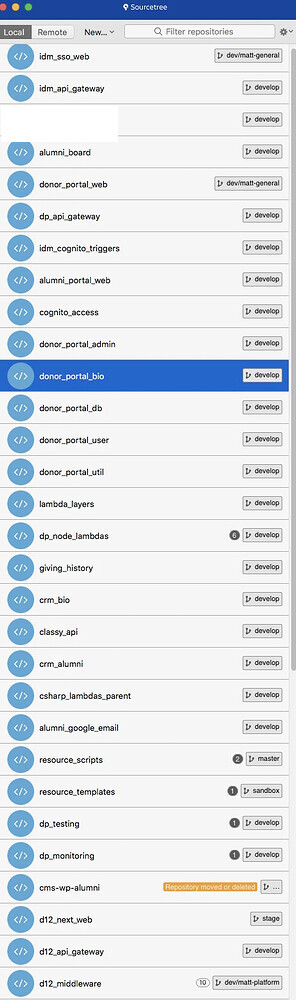
On this screen I can see at a glance which repos I’ve made changes to as I’m bouncing around from repo to repo implementing a cross-cutting feature (deep back end, orchestration lambdas, api gateway, front end react app, api integration tests, selenium/cucumber e2e tests, codepipelines, cloud formation templates, scripts to install AWS resources, and a bunch of other crap). I can also see which I’m behind on (the while number at the bottom).
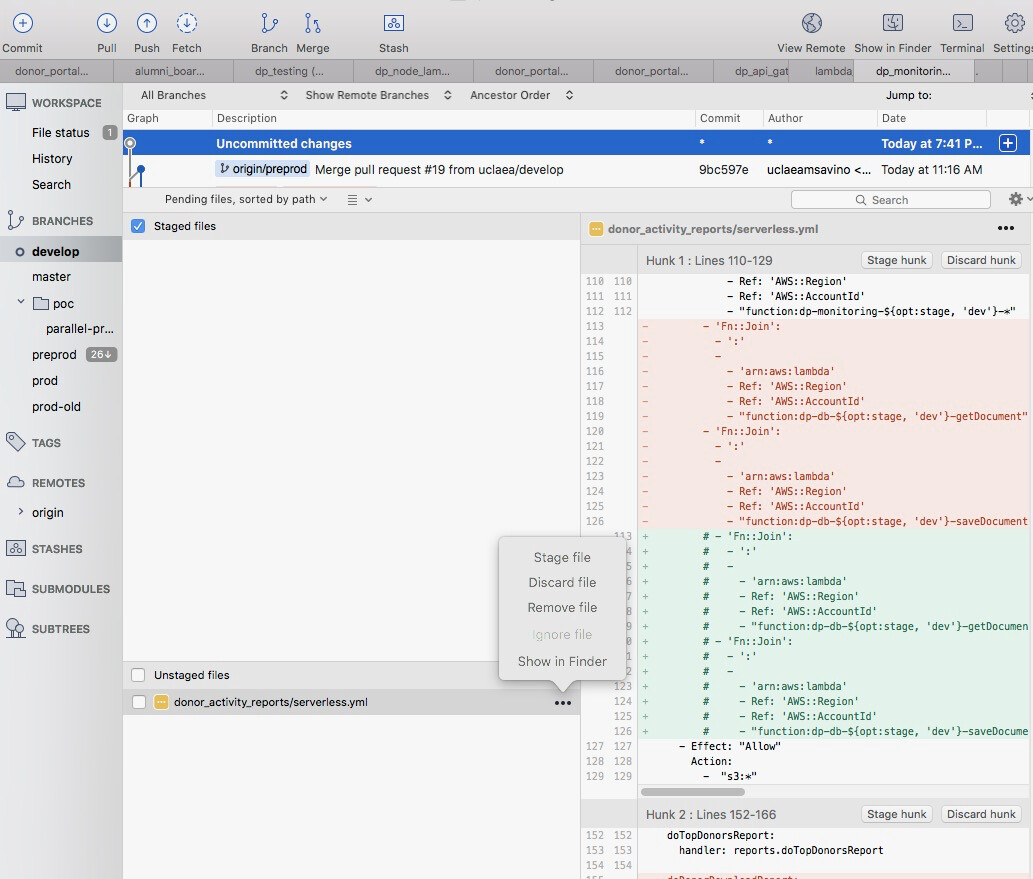
With this I can easily see all changes in a GUI, I can choose to discard all the changes (discard file - great for wanton debugging and POCs), or just choose to discard certain hunks (great for removing console.logs), I can doubleclick to launch the file in Sublime. It auto-pushes when I commit (source tree setting). There are some other goodies I’m forgetting.
And the usual reason for preferring a GUI - I don’t like having to memorize commands.
You can run an X11 server under WSL. I’ve done it and it’s kind of cool with a dual monitor setup. I think they just made it a lot easier too.
1 Like
Yeah, like a week ago I guess. There was a lot more screwing around with very typical Linux crap when I did it.
Microsoft and Apple are going to completely devour Linux.
1 Like
we don’t always need history, those are all in code reviews if you ever need to find them. we enforce single commits to master, which makes necessary reverts a lot easier
I almost never look at commits unless something goes horribly wrong. We use pull requests for that snapshot of a change.
if i have that many conflicts in consecutive commits, something went pretty wrong, probably by erroneously creating and merging an origin/master branch, instead of master from origin, working on a feature in local master, then pulling, or just cherry-picking like an idiot. i usually backout, squash my personal branch to something manageable and continue. if my feature has 34 commits, our code review tool (arc/phabricator) is going to freak out anyway.
ypu and me are probably touching on an area where code/repo guidelines are very different.
I use gui + commands. In your case I’d probably do that as well. There are not really a lot of git commands to know.
As far as discarding chunks or files that’s nice. For a file it’s easy, it’s just git rm (file name). But removing chunks of code - I guess I just vim, remove the lines, git add. Not really that much work but I guess it does take a few extra seconds.
I don’t trust automated git tools because they make mistakes sometimes or do what I don’t intend. I am a control freak and add most things file by file when I am committing to make sure I don’t commit something that’s potentially destructive or unnecessary.
Like my teammate is constantly committing .terraform directory because he uses IDE which just commits everything. until I got exasperated of always cleaning up his PR’s and added it to our .gitignore.
maybe I’m dumb and inexperienced but I’m still not seeing the need to rebase so often, in victor’s case. We go like this (and in most projects/teams I’ve worked on so far) -
- branch dev off of master
- make some commits
- (some commits happen in master)
- merge master back to dev
- pull request for dev to squash merge back to master
- profit?
I don’t see why you need to rebase unless something goes wrong. Yes, merging master back to dev can cause merge conflicts. I guess at that point you could just rebase and get rid of those conflicts. But conflicts exist for a reason - you could be overwriting someone else’s important work. I like to resolve conflicts by hand. I think this is more correct, imo.
lol I had a pull request recently with over 100. I can’t test locally so I need to push a commit, then run something in jenkins to see the result. really obnoxious.
1 Like
Some people doing work for me complained of slow SQL performance and when I investigated, SELECT * from a table with 350K rows takes 10 seconds from my home computer (already a bit slow, seems like), it takes 53 seconds from my accommodation here in Melbourne and a whopping 2 mins 42 seconds from the offices of these guys. The internet in all these locations is otherwise generally fine and the cloud server is located in Sydney. Any ideas how I can go about troubleshooting this? I have no idea what I’m doing with sysadmin stuff.
Edit: Also I just test-downloaded a file from the cloud server both here and at home, speeds looked basically identical but the SQL result set transfer is 5x slower here, very weird.
It sounds like an inefficient custom protocol for the sql client. Is there a VPN involved or are you connecting over open internet?
Open internet and it’s SSMS in all cases (connecting to MS SQL Server).
Very general thoughts/question/request for comments:
When you have a bunch of data that a user is interacting with multiple times you can make entries into db and get info from db to present to user after each change in the db. Or you can change the data they see in javascript to either remain consistent with what you “know” the db to be or you can save up a bunch of stuff in JS and make it clear that no changes have actually been made while the user was interacting.
They all seem to have plusses and minuses to me and I have recently done two different projects and done them differently each time. I hope for reasonable reasons. On a project where I think not matching the data for a minute is not that big a deal, I’ve elected to keep the user looking at changes made in JS (React) so that they get no page reloads. In one where I’m just worried that down the line somehow the JS ad DB get out of sync (I will not own this code forever - someone else will), I’ve elected to make sure every view/change is coming from the db info. This has led me to sometimes having to come up with ways to pass info between db and javascript using the path and hidden form elements so that the presentation can be right (like having the correct choices on a form selected/highlighted).
No specific question, other than, does this sound normal? Sound like decisions you commonly make? (and not tied to any particular technology other than things that happen on the server vs things that happen on the browser)