I feel like all of this stuff is bunk to some degree, and I’m not willing to put a ton of stock into it. Instead, I prefer to look at all of it as a constellation of information and downplay individual pieces. Switching gears a bit but are you familiar with adjusted plus-minus models for NBA (and NHL)? It’s a very different type of estimation problem since you’re trying to get coefficients of variables that mostly coexist (the same players tend to be on the court at the same time). So for instance, the data structure may look like this:
Plus_minus, Possession, Home_1, … , Home 5, Away_1, … , Away_5
-1, 1, Lebron, … , Westbrick, Steph, …, Klay
0, 2, Lebron, … , Westbrick, Steph, …, Klay
.
.
.
1, 100, Lebron, … , Westbrick, Steph, …, Poole
That’s oversimplified but the point here is that each player is an indicator variable with his own column, and you regress the point differential (+/-) onto the on-court players for a given unit of time / possession. So in theory it makes sense that you could get beta estimates for each player’s effect on the scoring that goes beyond things that are directly measurable like box score stats…
Except I’m sure you already see the problem here. The variance at this level of granularity is already large, but also there’s massive multicollinearity since the same players tend to be on the court at the same time a lot. The result you’d get from stock OLS regressions are wildly inefficient estimates that aren’t converging anytime soon and that amplify even minor misspecifications, and even miniscule changes in the data can lead to dramatic shifts in the outputs.
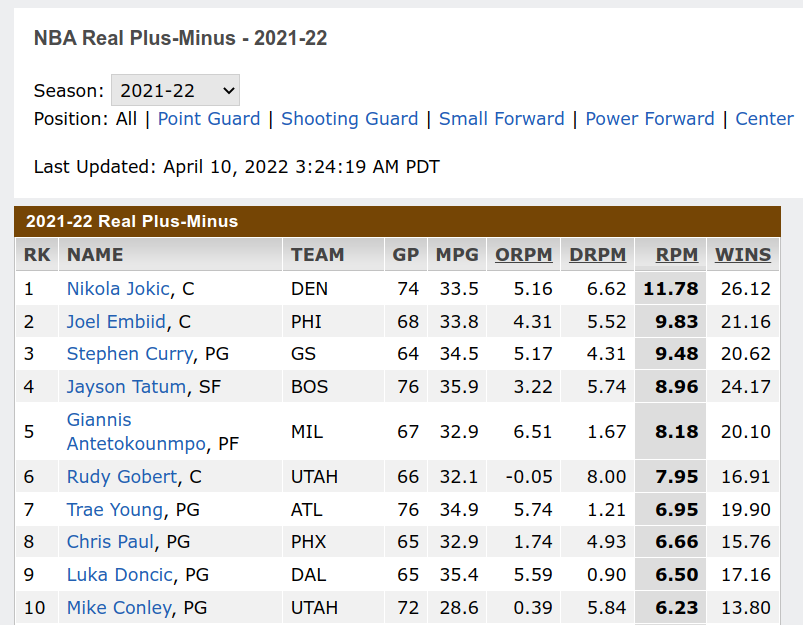
Luckily we have penalization techniques like ridge regression, and those are exactly the types of methods used for this particular modeling that handle the limitations of the data, which, as far as I know, were mostly developed by the good people over at APBRmetrics forum, the SABR of basketball. Even ESPN has been publishing an RPM model for NBA since 2014 along with concomitant WAR estimates.
So that’s a happy ending to this sports analytics story, right? Right??? You’ll have to imagine the Star Wars jpg and also the sound of this sad trombone I’m about to play:
We extend the analysis by using ESPN’s estimated values as explanatory variables in a set of fixed effects and the two-stage least square (2-SLS) regressions that seek to explain player-season APM variation.
The results provide strong evidence that regularized adjusted plus minus player productivity measures are not, in fact, “teammate-independent.” Rather, we find evidence that lineup-teammate productivity positively influences a given player’s real plus minus value. As this result is conditional upon a given player’s baseline productivity via player fixed effects and age, we interpret this as a significant and fairly strong complementarity effect that is uncontrolled in adjusted plus minus measures such as real plus minus.
Based on the estimations above, for each unit average gain in the teammate’s RPM, a player’s RPM is overestimated by a range of 0.17 to 0.66 points according to point estimates. We find that RPM is not context-independent.

Like holy shit that’s an enormous amount of bias in the ESPN estimator. There’s a ton of endogeneity here, and I’m not aware of any popular NBA APM model that controls for it (because it’s hard and maybe impossible). The annoying part, and the point I’m attempting to make here, is that none of this is surprising for people who are trained to do this kind of work. Every economist I know would have quickly raised objections over endogeneity in this data.
So that’s interesting but what does this have to do with baseball? My impression from hanging out at APBR is that the people over there are much sharper and have more knowledge than the people doing SABR. At least the models and techniques they use are real ones used in modern science, and while penalized regression may not be quite good enough for plus-minus, and some combination of fixed effects / 2SLS or instruments may be required (if possible), that discussion is at least germane w.r.t. how this stuff actually works. Baseball data seems to present unique problems that are dissimilar to basketball and other sports, but I’m equally skeptical that it holds up at this level of scrutiny. In fact, I’m more skeptical.