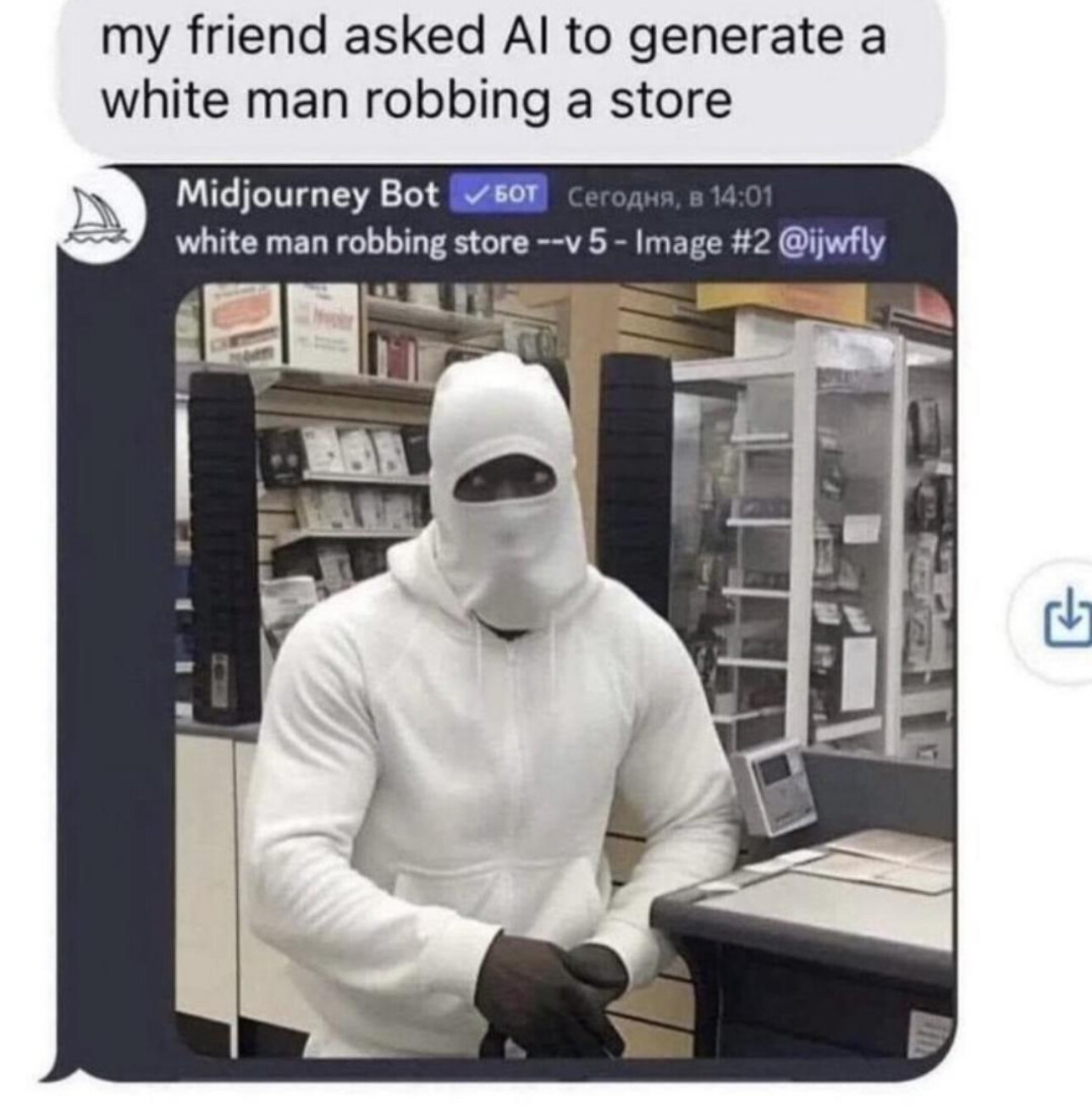
Yeah, it’s absolutely motivated reasoning. If you start off convinced that GPT reasons fundamentally differently than humans, you can find some “evidence” to confirm that hypothesis.
One thing that regrettably flew under the radar was the guy who did an experiment with a non-chat tuned GPT-3.5 model and found that it could play a strong game of chess. It’s such a shocking finding that I’m reluctant to put a ton of weight on it without confirmation, but assuming it’s true, it’s pretty ironclad evidence that LLMs learn abstract models from text. Once you understand that, the only question is which domains the LLM is using conceptual models for and which ones are being handled by memorization or guessing.
But even ignoring the chess example, if you work with these models long enough, the hypothesis that there’s no conceptual reasoning going on will quickly become untenable. This happens very soon for software people, because LLMs are really strong at code. If you go looking for them, you can find lots of mistakes too, though. But mistakes (notably, something that happens to humans too!) don’t prove the absence of true reasoning. If a model fails at nine tasks that require reasoning and succeeds at one, that proves that the model can reason, not that it can’t!