Yeah, there are definitely some flags that I see, then by the time I have the energy and time to dedicate to actually investigating the context, they are gone. I feel like this is a problem, but I honestly don’t know how to fix it.
Memory use has doubled for the server out of nowhere a few days ago.
We’re fine, but, I need to intervene pretty soon. I don’t want to find out what happens if the server goes OOM. I am going to look into the issue tonight and try to get up early to fix it. Hopefully it is nothing a restart won’t fix.
There is also a new version, 3.8.0beta. Let me know @anon46587892 what you think of upgrading. Will everything on the front break? We may have no choice. I don’t know yet. I’m going to go to their forums and get some guidance on the issue if restarting/cleaning does not resolve it. Usually with these things it does.
I want to repeat that everything is fine, but it is a fairly perplexing issue that must be dealt with sooner rather than later. It’s very bizarre.
1 Like
Ok. I might upgrade at some point if this persists. Like I said before - I would upgrade on new minor versions. There is a new minor version, 2.8.0beta. I’m gonna hold off for now. I’m going to seek advice on discourse forums and see what the feedback is.
I stopped and restarted the discourse container. It looks like that improved things. Most of our memory use was in cache - which is not a problem really. However, what freaked me out is I could not connect to the server via digitalocean’s UI. I get OOM messages.
Luckily, being the paranoid fucker I am, I installed a backdoor a while ago. My mac laptop can directly connect to the server. That worked fine, and I was able to restart the instance.
Memory usage before looked like this (notice the huge spike out of nowhere):
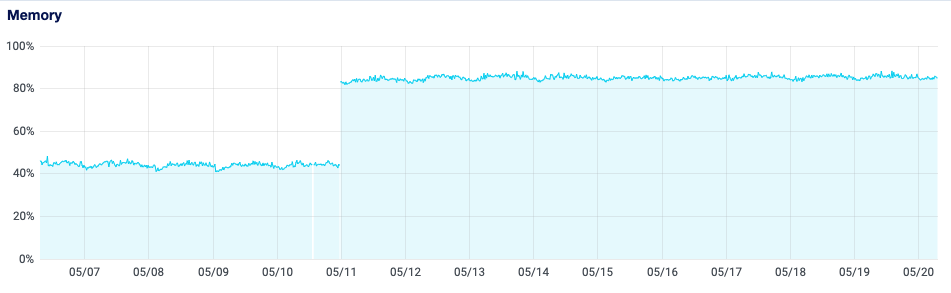
Now it looks like this:
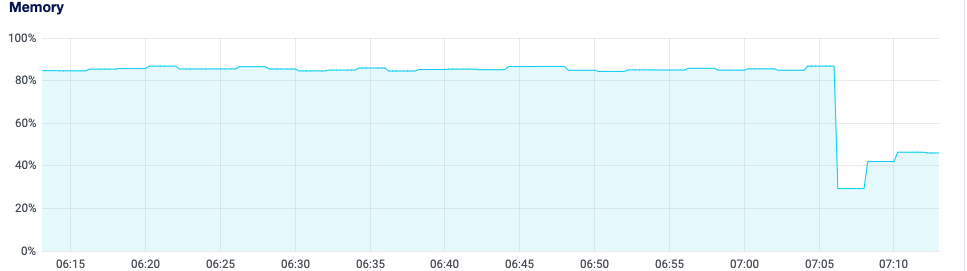
Here is the memory info from free before the restart:
$ free -h
total used free shared buff/cache available
Mem: 7.8Gi 3.2Gi 339Mi 3.1Gi 4.2Gi 1.2Gi
Swap: 0B 0B 0B
And 10 mins after:
$ free -mh
total used free shared buff/cache available
Mem: 7.8Gi 2.3Gi 1.5Gi 1.2Gi 4.0Gi 4.0Gi
Swap: 0B 0B 0B
Significantly better. I’m going to continue to monitor this. We normally get huge memory spikes when backing up the forum (once a week). I am going to this weekend set up some monitoring tools that will alert me via email when these things happen so I’m not noticing them an entire week later (I usually check like ~once a week).
Anyway, if you have no idea what I’m talking about, things are fine. Just a briefly scary moment due to an issue I have not yet diagnosed, but restarting seems to have fixed it. Will investigate further.
Anyway - @spidercrab (you do the money right?) I would feel a lot better if we increased the server’s memory. I don’t know at this moment what that would cost. This is definitely the lazy way out though, so I’m going to continue diagnosing.
Despite the fact that 90% of this goes over my head, I enjoy reading these updates and appreciate the work that you’re putting in jmakin. Thank you!
4 Likes
I don’t really think I’m a good judge for whether this would be worth it, but I’m assuming it would be. It does remind me, again, that I need to post a financial update.
1 Like
I’m still seeing this issue and seem to have gotten the attention of the creator of discourse:
Seems like we may not be the only ones. Could be host related? I’m not really sure how that could be, but I guess it’s possible. Anyway - if I can’t fix this we need to resize our droplet. That will double our bill to $80/month which sucks. Does that put us in the red?
Did you reboot the server or just restart the container? It might not have anything to do with Discourse.
1 Like
Going to try rebooting droplet next, but can’t get to it til this weekend
I second this question. When you posted your description of the problem/situation, which said you couldn’t connect to the server via the Digital Ocean tools, but could connect directly with your laptop, I thought it seemed like there could be a problem with the container environment rather than the Discourse app/server.
I rebooted the discourse container, if that was not clear
Yeah, sorry, ignore that. I don’t know what is what with containers and dockers and stuff. All my webserver work has been on “old-fashioned” servers where stuff runs directly on the server’s native OS.
This is really stressing me out :/
It’ll be fine but it’s gotta have a fix and soon. I don’t think we’re using swap - I’ve never configured that but it doesn’t look too bad.
Can you unplug it and plug it back in? Bang on it with your hand a few times?
that is roughly what i’m gonna try in the morning.
Don’t forget to blow on it once you pop out the cartridge.
2 Likes
We are not using any swap. We shouldn’t need it. It’s very inefficient and only recommended for dinky little servers with no resources.
Just reboot it and see what happens. Takes like 90 seconds. If that doesn’t fix it I’d look into doing some sort of Postgres cleanup.
1 Like
I just stop the container, restart the instance, then restart container, correct?
You don’t even need to bother with that. shutdown -r now is all you need to do. Everything will exit gracefully and come back up on its own.
Are you still doing unattended upgrades? I used to have to reboot like twice a month to keep the system current.
1 Like
Don’t cross the streams.
restarted the VM again