Riverman I’m unsure what youre talking about, those polls are great.
1 Like
No, it’s probably a combination of luck and skill. A pollster with zero bias would need a lot of luck to have all their results be so close to the true outcome, but a pollster with significant bias would need a ton of luck. Even over small samples, it adds up quickly.
1 Like
The time to make that sort of adjustment to your methodology would be before you do the poll, not after you get the results and decide you don’t like them. You should reports the results you get, or else you’re just reporting your feelings and not doing a statistical poll.
3 Likes
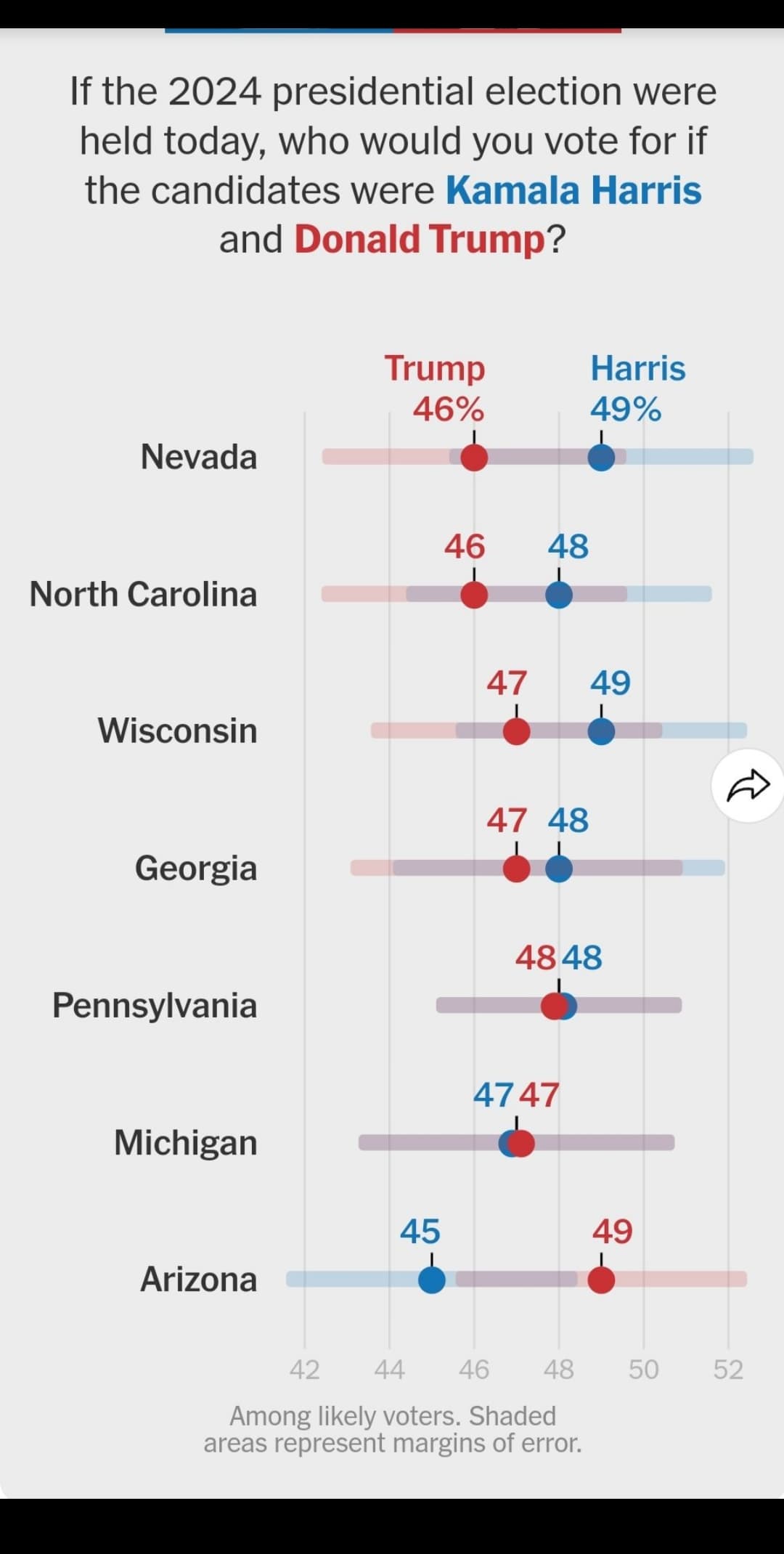
It’s weird because if that is true, Harris should be crushing in Wisconsin and Minnesota as those have pretty similar demographics to Iowa, and then struggling in Nevada, and Georgia but the other polls aren’t showing that type of shift.
1 Like
Before and after is kind of a red herring. You’re going to see anomalously pro-Harris and pro-Trump results. If your model compresses that variation into your prior about where the race is, then you’re herding, and your well-behaved uncorrelated errors turn into systemic, shared biases
1 Like
Keep my school out of your mouth. We know nothing about math.
How many pollsters are there in our set being assessed?
Paying attention to polls right now has to be among the most emotionally -ev things a person can do. It’s pure downside.
4 Likes
he’s so fucked
2 Likes
Yes but somebody showing the Iowa poll to Trump is just such a delicious scene. Anybody within 20 feet of that whiny bastard is hearing about it nonstop. But the farmers!
7 Likes
I hope you’re right because one of the candidates is doing just that.
1 Like
There isn’t a well-defined answer to that question. For me, the sample size is 1. This pollster put out a shocking poll, and the natural first question is “Is this specific pollster any good?” And the answer to that question is that this pollster has performed strikingly well in the past.
Did pollsters always do this “model the composition of the electorate” thing? Or historically did they just call a random sampling of voters and report the results?
I mean. You must know why I think that’s not the right approach. Why do you think it’s one?
Maybe you could simply state the position you believe to be true and explain why? My point is that there’s an important distinction between selecting something based on prior success vs selecting someone based on something else (in this case, releasing a surprising poll). N=1 is probably not right, because there are doubtless other surprising polls that didn’t get much attention because they dismissed due to the producer’s weak track record. However, it’s still closer to N=1 than N=all polling firms.
I get what you’re saying, but it seems odd mathematically to say the results of a poll, which is an aggregate of data, is a sample size of N=1.
That’s not what I’m saying. I’m saying that you need to distinguish between the case where you pick the pollster with the best track record vs picking a pollster for some other reason and examining their track record. In the former case, you should require a much more impressive track record to think they’re really good.