Hydration scripting is configuring VMs with scripts and is mostly a windows thing. Basically I am a midlevel administrator with some network security focus so the idea is to automate the creation of the VMs so that I can pentest and then easily put them back together again later. A lot of windows stuff is not well suited to this unless you use a precreated image since the software often cannot be configured properly with scripting. I’d like to get my CISSP in the next few years and build my administration skillset before pivoting to pentesting.
I had to google, “Where did Add to Favorites go on iOS Safari?” and I still wasn’t getting any info - which told me it must be something really stupid. Wanna guess? Yeah - not only do the bottom two rows scroll right to left, which is obvious - the whole bottom panel thing also scrolls up to reveal more stuff, which is beyond not obvious (there are other panels and cryptic icons where it could be hiding as well). This is an iPhone X so it’s no some old/odd screen size.
Terrible terrible UI. You scroll it up enough so it’s not perfectly in between rows of stuff. Everyone knows this.
I swear Apple must employ 100s of engineers and product people whose sole job is to make each successive release of all their user interfaces more confusing and counterintuitive. But goddam I bet they can bubble sort the shit out of that whiteboard interview.
2 Likes
And make like $350k/year to put out this crap.
I’m not bitter.

5 Likes
Nice. I wish I had more windows skills but I’ve gone too far down the unix rabbithole.
Lmao. Yea so true for a lot of the tools we use that are OSS
Deployed my first live server that’s being used by some other teams. Been all stressed something’s gonna go wrong, but it should be solid. No one’s pinged me that their entire world is on fire yet.
I became “the guy” that knows the most about this tool we are switching over to, so now I’m getting assigned all these issues related to its deployment. It’s exciting but a little stressful.
2 Likes
I’m taking a c++ class with nanodaughter thanks to Zoom.
#include <iostream>
#include <vector>
#include <string>
using namespace std;
int main()
{
vector<string> msg {"Hello", "C++", "World", "from", "VS Code", "and the C++ extension!"};
for (const string& word : msg)
{
cout << word << " ";
}
cout << endl;
}
and this
#include <iostream>
#include <vector>
#include <string>
using namespace std;
int main()
{
vector<string> msg {"Hello", "C++", "World", "from", "VS Code", "and the C++ extension!"};
for (string word : msg)
{
cout << word << " ";
}
cout << endl;
}
have the same output. What’s the difference? What’s the point of the “string&” in the for statement? The first way is from the Visual Studio installation hello world example and I was trying to figure out what the point (no pun intended - I believe it has to do with pointers) is if the seemingly more straightforward way does the same thing.
1 Like
My wife just applied to her first back end bootcamp. Nervous and excited for her
3 Likes
Yikes start with python or javascript
1 Like
I’m used to C so that just looks like syntactic sugar to me. But it has to do with how your program allocates and references memory. Look up “pass by reference vs pass by value”
Here is a good SO thread:
1 Like
Pass by reference means your function (in this case the for loop) has a pointer to the variable instance supplied as the argument “word”. So any changes you make to that variable will be reflected to any other code that accesses the instance.
Pass by value means your function has a copy of the variable. So you can mutate it all you want w/o worrying about side effects.
Sometimes you want the first thing, sometimes the second. Although some purists will argue that a function should never mutate an argument. I tend to agree that that mutating arguments should be avoided if possible - as it makes for convoluted code. In your case it doesn’t make a difference because you’re not mutating the argument “word”.
Try changing the “word” variable in your for loop in each case (word = word + “x” - or whatever the syntax is in C++). Actually the const keyword prevents you from doing that, so you may need to remove it to see this demo. After the for loop, spit out the vector “msg”. Unless C++ is weirder than I remember, msg should be unchanged for pass by value, but changed for pass by reference.
Java, Javascript and C# just decide for you. If the argument is an object, it’s pass by reference. If the argument is a primitive, it’s pass by value. (primitive = int, string, float, double, boolean, etc)
1 Like
Nanodaughter is taking C++ (just started college intending to be a CS major and it is required - weirdly they put python after C++, she took an AP class that did javascript). I’m going to take the course with her.
1 Like
If she struggles with pointer vs. copy - you might try explaining it like this:
If I send you an email with a word document attached, you have a copy of my word doc. You can edit it all you want and it won’t affect my original.
But if I send you a link to my google doc (with privileges), you have a pointer to my original document. So if you change it, you’re changing my document.
In both cases if all you do is read my document - it’s functionally the same.
Programming concepts are so much easier to explain in the internet age. Twitter = pub/sub. Email = asynchronous communication.
1 Like
Thanks. I’ll play around with that a bit. The second example I assume is not mutating “msg”, but I’ll check. The first example creates a new copy of “word” on each iteration? I’ll check. Thanks.
Neither example is mutating “msg” as shown in your post. But if you change “word” inside the for loop (by say concatenating another string onto it), I believe it should mutate the individual elements of the original vector “msg” - but only for the pass by reference case (string&). I think it could be a good demo to help see the concept in action.
I’m not 100% sure how to “spit out the vector” in C++ though. You could just repeat the for loop but w/o the mutating.
Cool. I did what you were talking about and it did mutate msg
vector<string> msg {"Hello", "C++", "World", "from", "VS Code", "and the C++ extension!"};
for (string firstword : msg)
{
cout << firstword << endl;
}
for (string& word : msg)
{
word = word + " there";
cout << word << " ";
}
cout << endl;
for (string thirdword : msg)
{
cout << thirdword << endl;
}
cout << endl;
output
Hello
C++
World
from
VS Code
and the C++ extension!
Hello there C++ there World there from there VS Code there and the C++ extension! there
Hello there
C++ there
World there
from there
VS Code there
and the C++ extension! there
1 Like
General C++ Kenobi
1 Like
I also find it helpful to draw out what’s going on in memory. So in your example (I’m pretty sure) memory is laid out like this:
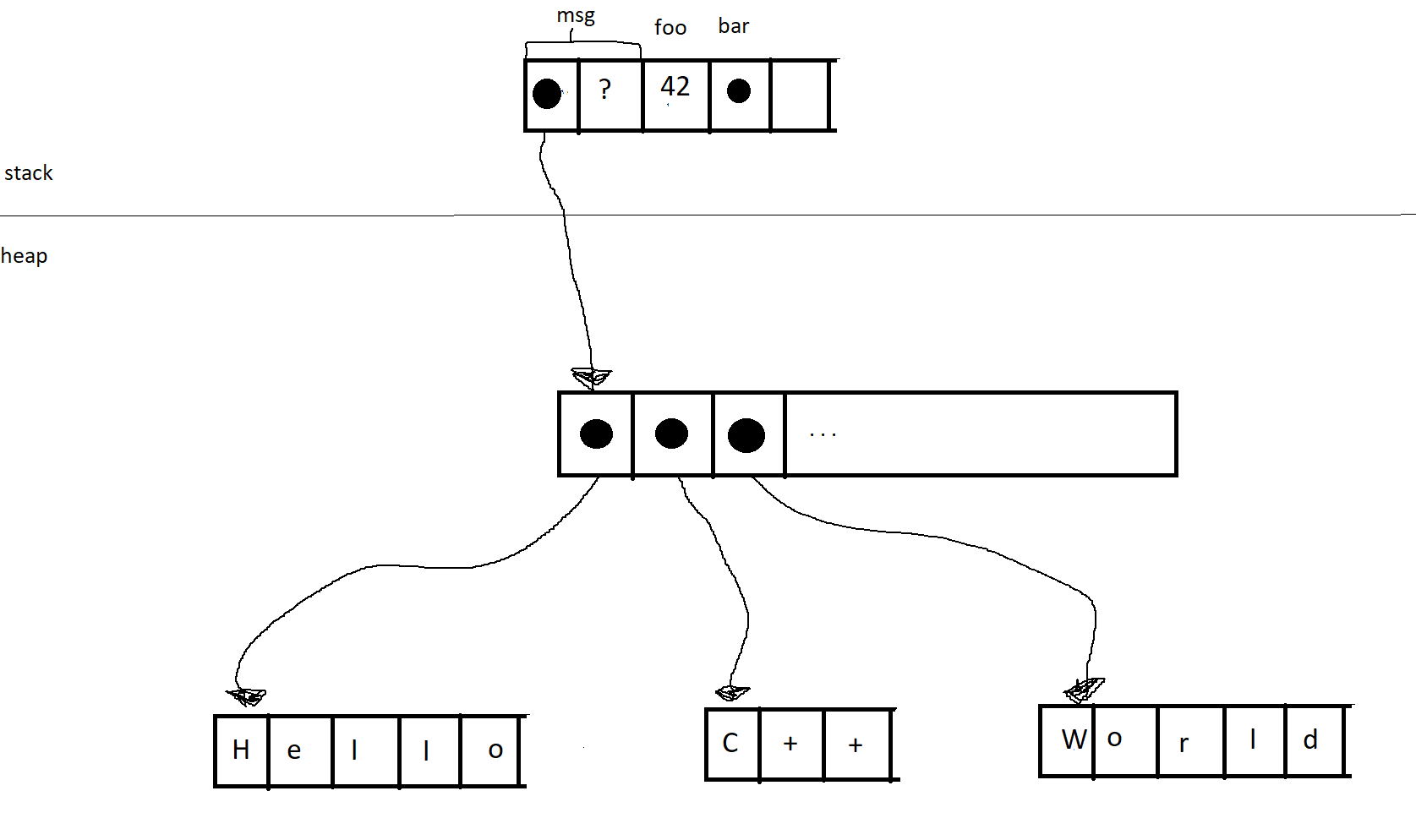
(Dots being pointers and the question mark representing internals of the vector data structure. Each item in the vector is itself a pointer (+ internals not shown here) to a different place in the heap where the letters are.)
You then need to create word. In the first example, you end up with the following:
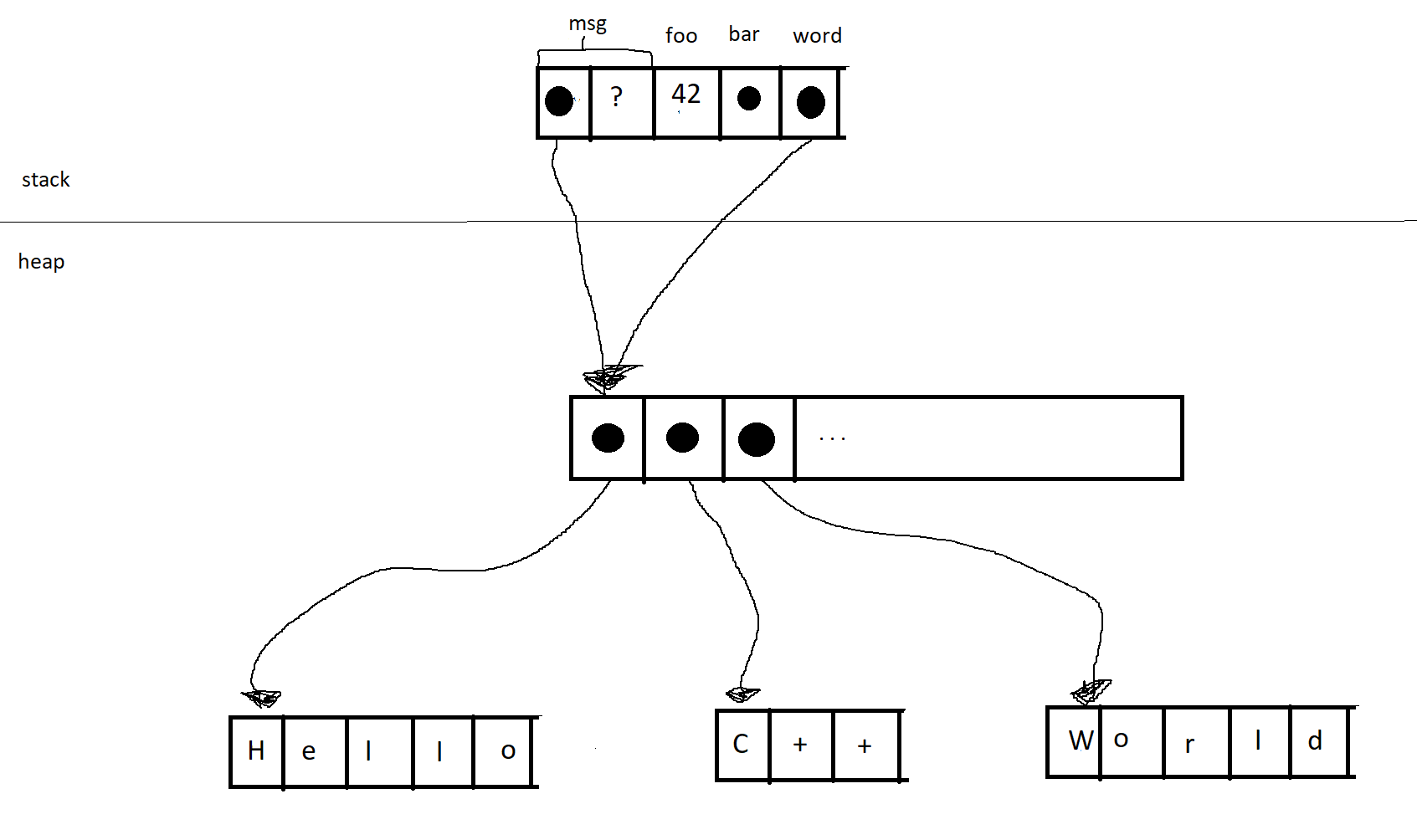
In the second iteration of the loop, the pointer will point to the second box, and so on.
In the second code example, you get this instead:
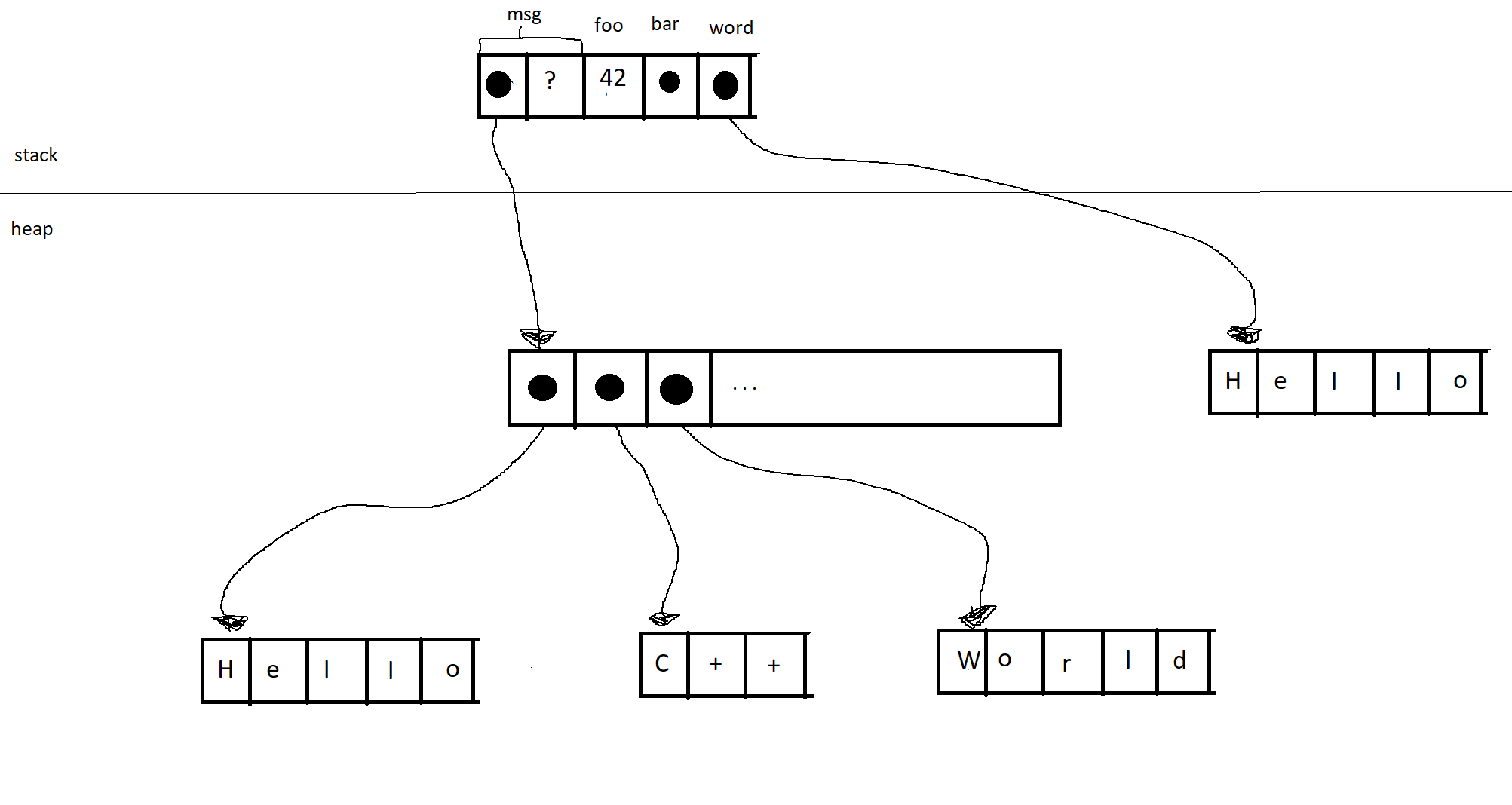
(Note that word is not actually just a pointer, it also has whatever internal data a C++ string has, but I didn’t draw them in the vector, and now I’m going to have to live with the consequences of that decision.)
A couple points to note:
-
In the second method (pass-by-value), you actually build up a new data structure for the loop to operate on. This would be a big deal if the string was, for example, the contents of War & Peace (or maybe What Is To Be Done? is the favored Russian lit around your place?) rather than a single word. Especially since
wordonly lives for one iteration of the loop, then gets dropped. -
What does not happen is this (two strings backed by the same memory):
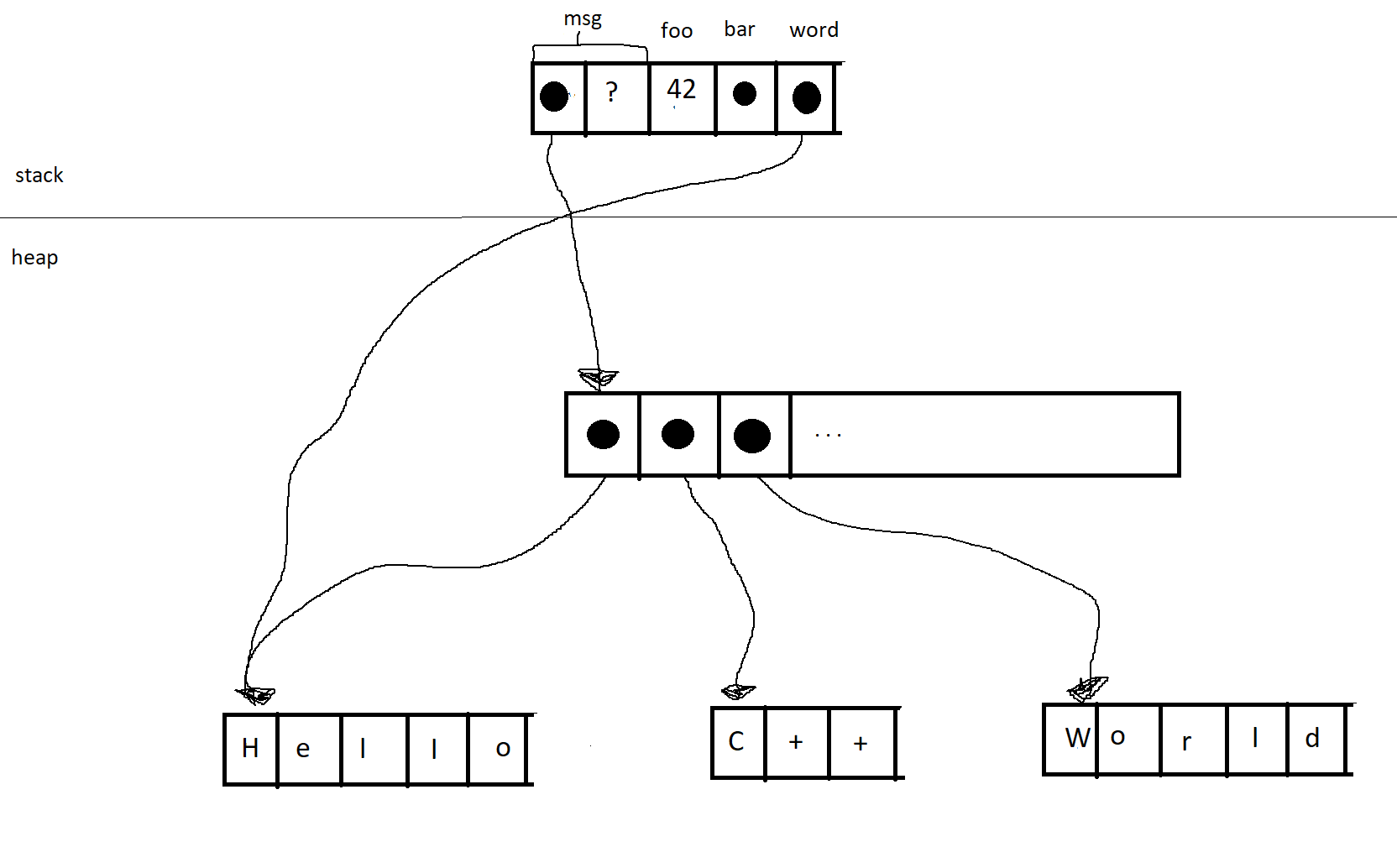
This would be a problem in C++ for two reasons. First, msg could see its data get mutated in ways it doesn’t expect. Second, and more important, it would no longer be clear how the memory gets released back to the OS. word can’t free the memory because msg might still need it, and msg can’t free the memory because word might still need it. (In this case, the lifetime of word is bounded by the lifetime of msg, so msg actually could free the data and it would be fine, but in more complex cases that wouldn’t be knowable.) You would need to create a new data structure that would track who still needs the memory and be responsible for freeing it when it’s not in use any more, which would create overhead. (Interestingly, this wiki article on the byzantine history of the C++ string indicates that strings actually did work that way once upon a time…). Also interestingly, in Python you would end up with two pointers to the same memory. That works because all strings in Python are immutable and all objects in Python are behind exactly the kind of data structure that tracks who’s using the memory and frees it when it’s no longer needed.
3 Likes
Thanks suzzergoofybob.